
The Unix Shell
Pipes and Filters
Learning Objectives
- Redirect a command’s output to a file.
- Process a file instead of keyboard input using redirection.
- Construct command pipelines with two or more stages.
- Explain what usually happens if a program or pipeline isn’t given any input to process.
- Explain Unix’s “small pieces, loosely joined” philosophy.
Now that we know a few basic commands, we can finally look at the shell’s most powerful feature: the ease with which it lets us combine existing programs in new ways. We’ll start with the directory called InSitu_Data that contains four files describing some vegetation measurements. The .cvs extension indicates that these files are in Comma Separated Values format, which is used to store tabular data (numbers and text) in plain text. Each record consists of one or more fields, separated by commas. The use of the comma as a field separator is the source of the name for this file format.
$ ls InSitu_DataD17_2013_vegStr.csv D17_2013_vegStr_metadata_desc.csv lidarExtractedValues.csv SJERPlotCentroids.csvLet’s go into that directory with cd and run the command wc *.csv. wc is the “word count” command: it counts the number of lines, words, and characters in files. The * in *.pdb matches zero or more characters, so the shell turns *.pdb into a complete list of .pdb files:
$ cd InSitu_Data
$ wc *.csv 363 2093 54690 D17_2013_vegStr.csv
0 551 5884 D17_2013_vegStr_metadata_desc.csv
18 19 1769 lidarExtractedValues.csv
19 19 772 SJERPlotCentroids.csv
400 2682 63115 totalIf we run wc -l instead of just wc, the output shows only the number of lines per file:
$ wc -l *.csv 363 D17_2013_vegStr.csv
0 D17_2013_vegStr_metadata_desc.csv
18 lidarExtractedValues.csv
19 SJERPlotCentroids.csv
400 totalWe can also use -w to get only the number of words, or -c to get only the number of characters.
Which of these files is shortest? It’s an easy question to answer when there are only six files, but what if there were 6000? Our first step toward a solution is to run the command:
$ wc -l *.csv > lengths.txtThe greater than symbol, >, tells the shell to redirect the command’s output to a file instead of printing it to the screen. (This is why there is no screen output: everything that wc would have printed has gone into the file lengths.txt instead.) The shell will create the file if it doesn’t exist. If the file exists, it will be silently overwritten, which may lead to data loss and thus requires some caution. ls lengths.txt confirms that the file exists:
$ ls lengths.txtlengths.txtWe can now send the content of lengths.txt to the screen using cat lengths.txt. cat stands for “concatenate”: it prints the contents of files one after another. There’s only one file in this case, so cat just shows us what it contains:
$ cat lengths.txt 363 D17_2013_vegStr.csv
0 D17_2013_vegStr_metadata_desc.csv
18 lidarExtractedValues.csv
19 SJERPlotCentroids.csv
400 totalNow let’s use the sort command to sort its contents. We will also use the -n flag to specify that the sort is numerical instead of alphabetical. This does not change the file; instead, it sends the sorted result to the screen:
$ sort -n lengths.txt 0 D17_2013_vegStr_metadata_desc.csv
18 lidarExtractedValues.csv
19 SJERPlotCentroids.csv
363 D17_2013_vegStr.csv
400 totalWe can put the sorted list of lines in another temporary file called sorted-lengths.txt by putting > sorted-lengths.txt after the command, just as we used > lengths.txt to put the output of wc into lengths.txt. Once we’ve done that, we can run another command called head to get the first few lines in sorted-lengths.txt:
$ sort -n lengths.txt > sorted-lengths.txt
$ head -1 sorted-lengths.txt0 D17_2013_vegStr_metadata_desc.csvUsing the parameter -1 with head tells it that we only want the first line of the file; -20 would get the first 20, and so on. Since sorted-lengths.txt contains the lengths of our files ordered from least to greatest, the output of head must be the file with the fewest lines.
If you think this is confusing, you’re in good company: even once you understand what wc, sort, and head do, all those intermediate files make it hard to follow what’s going on. We can make it easier to understand by running sort and head together:
$ sort -n lengths.txt | head -1 0 D17_2013_vegStr_metadata_desc.csvThe vertical bar between the two commands is called a pipe. It tells the shell that we want to use the output of the command on the left as the input to the command on the right. The computer might create a temporary file if it needs to, or copy data from one program to the other in memory, or something else entirely; we don’t have to know or care.
We can use another pipe to send the output of wc directly to sort, which then sends its output to head:
$ wc -l *.csv | sort -n | head -1 0 D17_2013_vegStr_metadata_desc.csvThis is exactly like a mathematician nesting functions like log(3x) and saying “the log of three times x”. In our case, the calculation is “head of sort of line count of *.pdb”.
Here’s what actually happens behind the scenes when we create a pipe. When a computer runs a program — any program — it creates a process in memory to hold the program’s software and its current state. Every process has an input channel called standard input. (By this point, you may be surprised that the name is so memorable, but don’t worry: most Unix programmers call it “stdin”. Every process also has a default output channel called standard output (or “stdout”).
The shell is actually just another program. Under normal circumstances, whatever we type on the keyboard is sent to the shell on its standard input, and whatever it produces on standard output is displayed on our screen. When we tell the shell to run a program, it creates a new process and temporarily sends whatever we type on our keyboard to that process’s standard input, and whatever the process sends to standard output to the screen.
Here’s what happens when we run wc -l *.csv > lengths.txt. The shell starts by telling the computer to create a new process to run the wc program. Since we’ve provided some filenames as parameters, wc reads from them instead of from standard input. And since we’ve used > to redirect output to a file, the shell connects the process’s standard output to that file.
If we run wc -l *.csv | sort -n instead, the shell creates two processes (one for each process in the pipe) so that wc and sort run simultaneously. The standard output of wc is fed directly to the standard input of sort; since there’s no redirection with >, sort’s output goes to the screen. And if we run wc -l *.csv | sort -n | head -1, we get three processes with data flowing from the files, through wc to sort, and from sort through head to the screen.
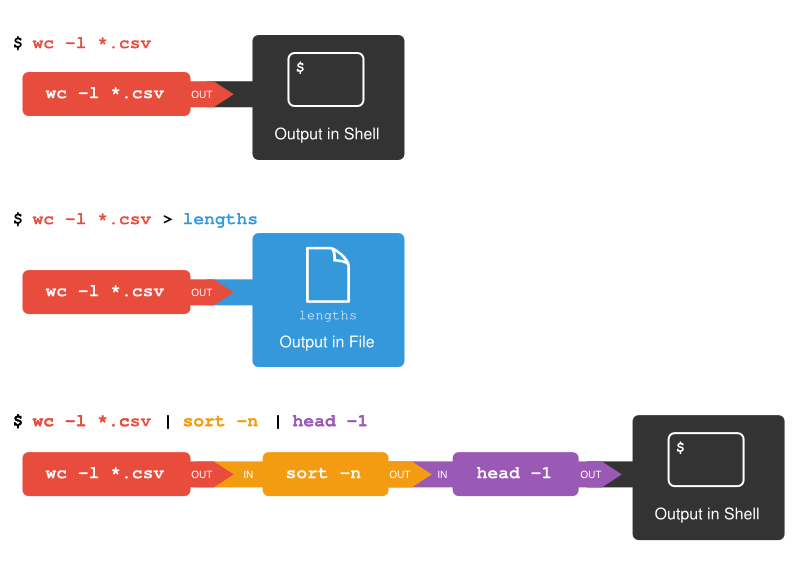
Redirects and Pipes
This simple idea is why Unix has been so successful. Instead of creating enormous programs that try to do many different things, Unix programmers focus on creating lots of simple tools that each do one job well, and that work well with each other. This programming model is called “pipes and filters”. We’ve already seen pipes; a filter is a program like wc or sort that transforms a stream of input into a stream of output. Almost all of the standard Unix tools can work this way: unless told to do otherwise, they read from standard input, do something with what they’ve read, and write to standard output.
The key is that any program that reads lines of text from standard input and writes lines of text to standard output can be combined with every other program that behaves this way as well. You can and should write your programs this way so that you and other people can put those programs into pipes to multiply their power.
What does sort -n do?
If we run sort on this file:
10
2
19
22
6the output is:
10
19
2
22
6If we run sort -n on the same input, we get this instead:
2
6
10
19
22Explain why -n has this effect.
What does < mean?
What is the difference between:
wc -l < mydata.datand:
wc -l mydata.datWhat does >> mean?
What is the difference between:
echo hello > testfile01.txtand:
echo hello >> testfile02.txtHint: Try executing each command twice in a row and then examining the output files.
Piping commands together
In our current directory, we want to find the 3 files which have the least number of lines. Which command listed below would work?
wc -l * > sort -n > head -3wc -l * | sort -n | head 1-3wc -l * | head -3 | sort -nwc -l * | sort -n | head -3
Why does uniq only remove adjacent duplicates?
The command uniq removes adjacent duplicated lines from its input. For example, if a file salmon.txt contains:
coho
coho
steelhead
coho
steelhead
steelheadthen uniq salmon.txt produces:
coho
steelhead
coho
steelheadWhy do you think uniq only removes adjacent duplicated lines? (Hint: think about very large data sets.) What other command could you combine with it in a pipe to remove all duplicated lines?
Pipe reading comprehension
A file called animals.txt contains the following data:
2012-11-05,deer
2012-11-05,rabbit
2012-11-05,raccoon
2012-11-06,rabbit
2012-11-06,deer
2012-11-06,fox
2012-11-07,rabbit
2012-11-07,bearWhat text passes through each of the pipes and the final redirect in the pipeline below?
cat animals.txt | head -5 | tail -3 | sort -r > final.txtPipe construction
The command:
$ cut -d , -f 2 animals.txtproduces the following output:
deer
rabbit
raccoon
rabbit
deer
fox
rabbit
bearWhat other command(s) could be added to this in a pipeline to find out what animals the file contains (without any duplicates in their names)?